
Previously I wrote a three-part series on classifying text, in which I walked through the creation of a text classifier from the bottom up. It was interesting but it was purely an academic exercise. Here I’m going to use methods suitable for scaling up to large datasets, preferring tools written by others to those written by myself. The end goal is the same: classifying and visualizing relationships between blocks of text.
Contents
Methods
There are three basic components being built:
- A representation of a block of text
- A classifier based on that representation
- Visualization method
I’m thinking of the classifier as a different representation of the block of text, so (1) and (2) are similar. Except that the output of (2) should have a clear and meaningful interpretation, namely, how likely a block of text is to belong to a particular class.
For a classifier I used fastText [1]. This method treats a block of text as a bag of word vectors. That is, it learns word vectors based on the corpus (which is done using an unsupervised deep neural network) and to represent a block of text simply adds all the word vectors together. I’m surprised this works, but then again, the bag of words model works surprisingly well. This should be one step above in both speed and accuracy.
For visualization I again use the tSNE algorithm, but this time the parametric version. The scikit-learn implementation of tSNE transforms one specific dataset and it cannot be reused for other datapoints. The parametric tSNE algorithm[2] trains a neural network using an appropriate cost function, meaning (among other things) new points can be transformed from the high-dimensional space to the low-dimensional space.
I implemented this in Python using TensorFlow and the newly-incorporated tf.contrib.keras functionality, the result is a standalone python package available on github.
The dataset is the same as previous work, and in fact what fastText uses as an example: 14 classes from dbPedia
Results
tSNE of all 14 dbPedia classes
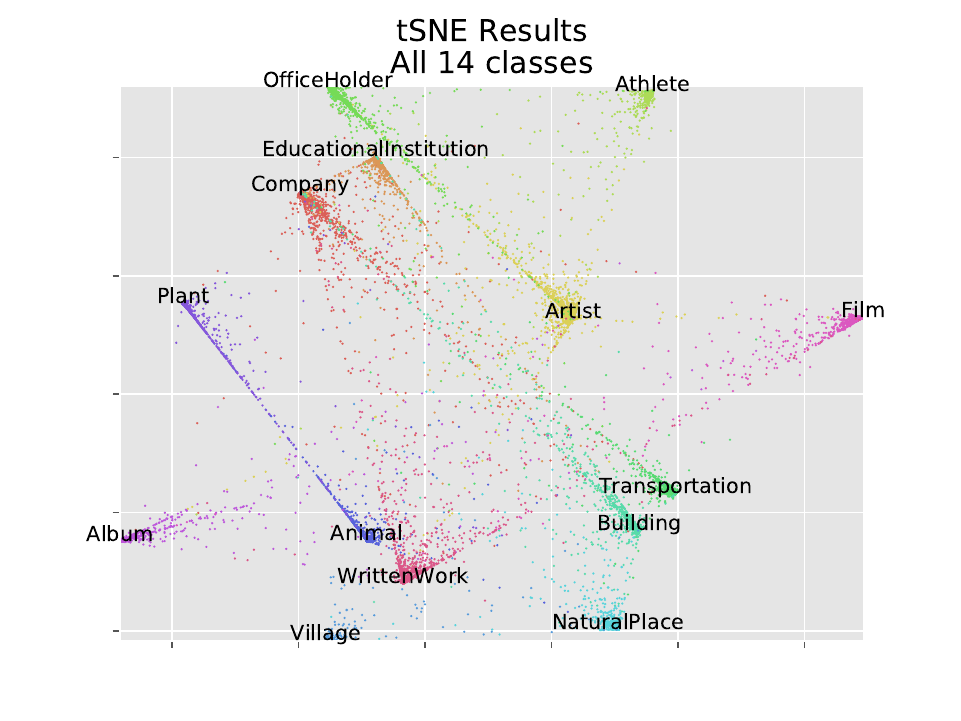
In contrast expectations from methods like PCA, classes which we expect to be similar don’t necessarily get placed closer together. The Plant and Animal cluster are distant, and Animal is closer to WrittenWork. Company, EducationalInstitution, and OfficeHolder are all near each other. There is an extremely mild correlation between the clusters, but if placement were done by correlation, Plant and Animal would be right next to each other.
There is evidence of that similarity in a different way. Many Plant and Animal points lie on a line running directly from one cluster to another. The same type of cross-talk is visible in other classes; WrittenWork, Film, and Company form a type of triangle.
tSNE excluding single classes
As a test of how this could work for unsupervised clustering, I re-ran the same analysis 14 times, excluding 1 class each time, building a model with 13 outputs instead of 14. Then running the excluded class through the model, we see how members of the excluded class get clustered. We visualize using our parametric tSNE, and also a joy plot of the log-probability of each class. In these tSNE plots we only plotted scattered points for the excluded class; contours are plotted for the other classes though they are hard to see.
14 x 2 plots is a few too many to show, so I’m just going to display a few of the more interesting ones (the full results are available in a here). We note that Artist, Athlete, and OfficeHolder tend to be close to each other. Each of these categories represent a type of person. Whichever is excluded gets split between the other two.
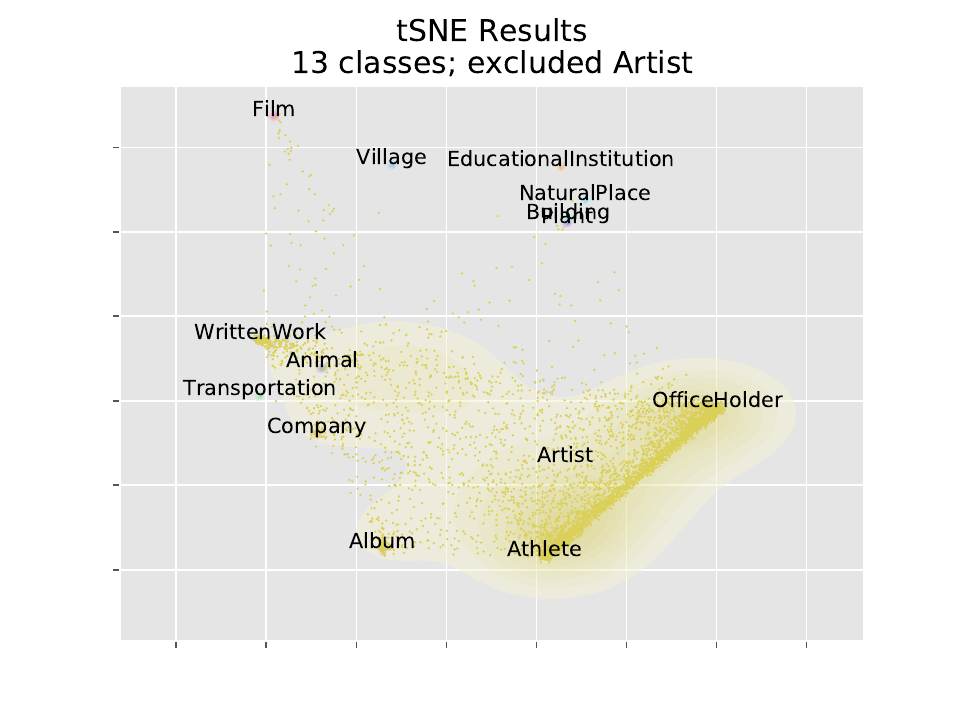
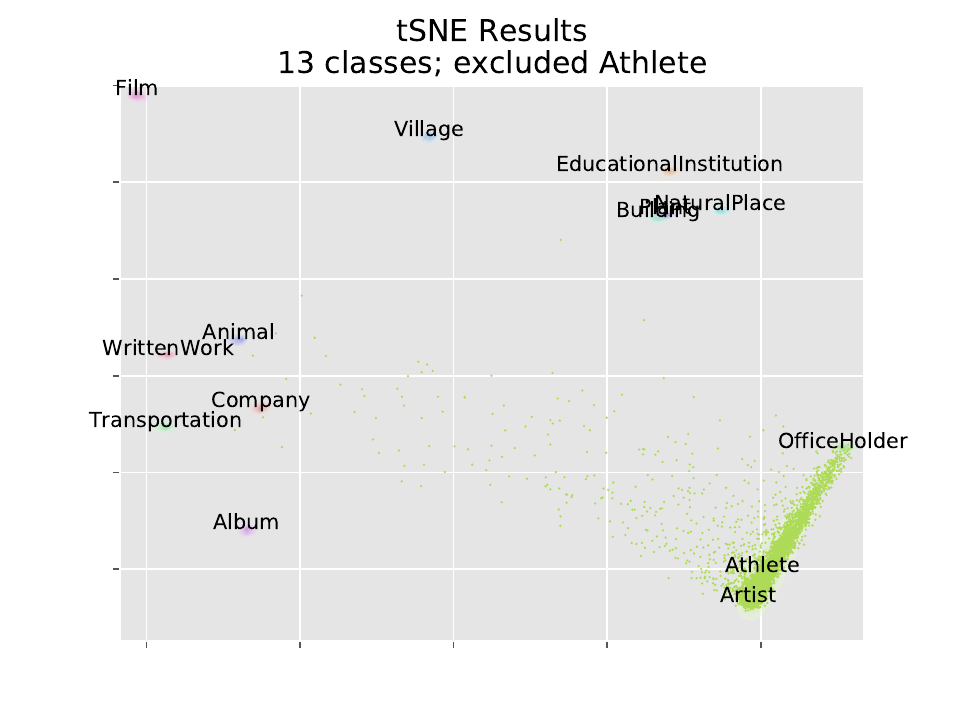
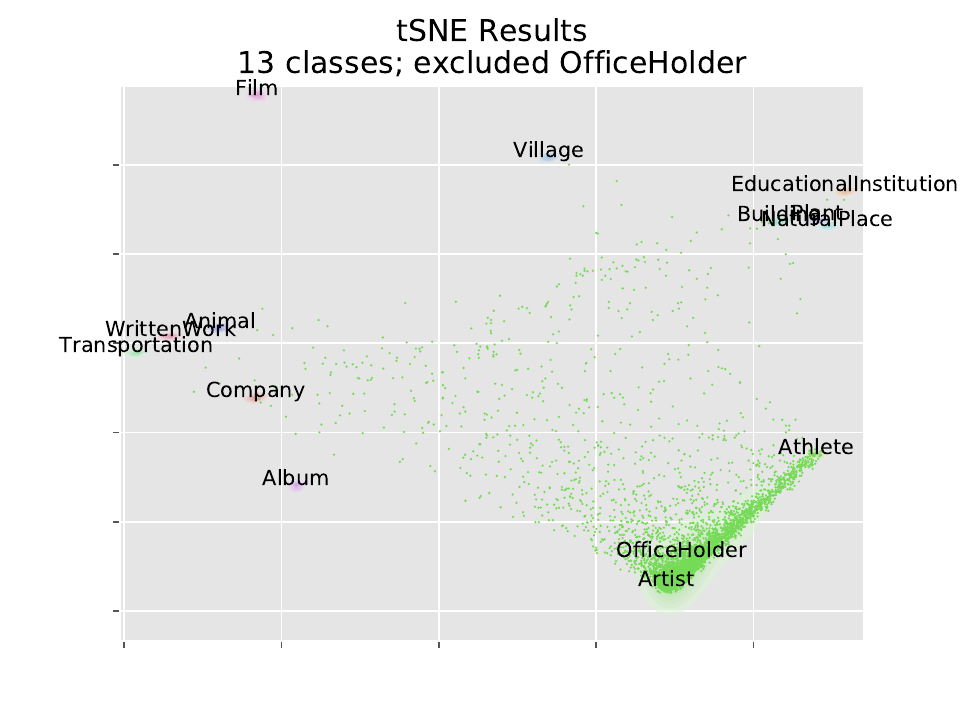 Example Points of Interest
Example Points of Interest
| Item Class | Item Description | Name |
|---|---|---|
| Plant | Halfway between Plant/Animal | chimonanthus salicifolius |
| chimonanthus salicifolius is a species of the genus of wintersweets chimonanthus and member of the family calycanthaceae . [citation needed] | ||
| Animal | Halfway between Plant/Animal | pseudomyrmex |
| pseudomyrmex is a genus of stinging wasp-like ants in the subfamily pseudomyrmecinae . they are large-eyed slender ants occupying arboreal habitats and occur exclusively in tropical and subtropical regions of the new world . most species of pseudomyrmex are generalist twig nesters for instance pseudomyrmex pallidus may nest in the hollow stems of dead grasses twigs of herbaceous plants and in dead woody twigs . | ||
| Building | Closest to Company | cliff brewery |
| the cliff brewery is a grade ii listed former english brewery. | ||
| Company | Closest to Building | captain cook memorial museum |
| captain cook memorial museum is in whitby north yorkshire england 43 miles (69 km) north of york . the museum is in walker’s house which belonged to captain john walker to whom the great explorer captain cook was apprenticed in 1746 and to which cook returned in the winter of 1771/2 after the first voyage . | ||
| EducationalInstitution | Closest to Company | cedu |
| cedu educational services inc . known simply as cedu ( pronounced see-doo ) was founded in 1967 by mel wasserman and his wife brigitta . the company owned and operated several therapeutic boarding schools and behavior modification programs in california and idaho. | ||
| Building | Closest to EducationalInstitution | roycemore school |
| roycemore school is an independent nonsectarian co-educational college preparatory school located in evanston illinois serving students in pre-kindergarten through grade 12 . the school ' s current enrollment is approximately 315 students. | ||
| OfficeHolder | Closest to Artist | dénes gulyás |
| dénes gulyás (born march 31 1954) is a hungarian tenor. a native of budapest he studied at the franz liszt academy of music in that city . | ||
| OfficeHolder | Closest to Athlete | oliver luck |
| oliver francis luck (born april 5 1960) is the director of intercollegiate athletes at west virginia university his alma mater . luck is a retired american football player who spent five seasons in the national football league (nfl) as a quarterback for the houston oilers (1982–1986) . he was also the first president and general manager of the houston dynamo of major league soccer (mls). | ||
The Plant halfway between Plant and Animal is distinguished by having many latin words, nothing to differentiate between a Plant/Animal. The Animal which is halfway between Plant and Animal has words like wasps, ants, arboreal, and tropical. “roycemoore school” is an interesting one; I would have called that an EducationalInstitution, and this classifier agrees, even though the dbPedia dataset has it as a Building. An OfficeHolder classified as an athlete (oliver luck) is a director of intecollegiate sports, and is a retired football player. Indeed, this illustrates a weakness of the bag-of-words approach, it has a hard time differentiating between the past and present.
Speed
The original goal of this endeavor was to scale up text classification efforts. So we should track how fast this method was compared to others. A comparison of this method compared to my previous one is in the table below:
| Step | Name/Tool | Time (mm:ss) | # Samples | Accuracy |
|---|---|---|---|---|
| Model Construction | TensorflowCNN/ LSTM | 51:59 | 560,000 | 91.90% |
| fastText | 01:18 | 560,000 | 98.50% | |
| tSNE Visualization | scikit learn tSNE | 00:22 | 2,000 | N/A |
| Custom parametric tSNE | 00:50 | 70,000 | N/A |
fastText is about 40x faster than the my previous Tensorflow CNN/LSTM. It’s also more accurate, although allowing the word vectors to be trained increases the accuracy of the LSTM that also slows down training. Presumably there are other improvements available which fit the same description.
Using parametric tSNE takes about twice as long as the scikit-learn implementation, but that’s partially because we are able to process an additional 68,000 points besides just the 2,000 used for training.
Conclusion
fastText worked well. The API needs some baking but the fundamental model is simple and effective. Parametric tSNE also worked well; it creates a reusable model which generalizes easily to other similar points. We trained on only 2,000 sentences but were able to transform an additional 68,000 into a meaningful visualization. All with runtime of 2 minutes. Not too shabby.
-Jacob
Links to Other Results
PDF of tSNE of all 14 classes: dbpedia_all_14_classes_tSNE
Tools and Datasets
Analysis code: https://github.com/jsilter/dbpedia_classify/tree/fasttext_ptsne/fastText
My implementation of Parametric tSNE: https://github.com/jsilter/parametric_tsne
fastText: https://fasttext.cc/, https://github.com/facebookresearch/fastText/
dbPedia:
Downloaded from https://github.com/le-scientifique/torchDatasets/raw/master/dbpedia_csv.tar.gz
Also available at here
Original citation:
J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer, and C. Bizer. DBpedia – a large-scale, multilingual knowledge base extracted from wikipedia. Semantic Web Journal, 2014

You note that classes that might be similar don’t get placed close together by t-SNE. This is expected, to some extent, because t-SNE focuses on local structure often to the detriment of global structure. I would be very interested to see what sorts of results you get under other algorithms like multi-scale t-SNE or UMAP which work to preserve more of the global structure while still providing a non-linear embedding.